
1.Вызов для современного стека данных блокчейна
Существует несколько проблем, с которыми может столкнуться современный стартап по индексированию блокчейна, в том числе:
- Огромные объемы данных. По мере увеличения объема данных на блокчейне индекс данных должен будет масштабироваться, чтобы справиться с возросшей нагрузкой и обеспечить эффективный доступ к данным. Следовательно, это приводит к увеличению затрат на хранение данных, медленному расчету метрик и увеличению нагрузки на сервер базы данных.
- Сложный конвейер обработки данных. Технология блокчейн сложна, и создание всеобъемлющего и надежного указателя данных требует глубокого понимания лежащих в основе структур данных и алгоритмов. Разнообразие реализаций блокчейна наследует это. Если привести конкретные примеры, то NFT в Ethereum обычно создаются в рамках смарт-контрактов, следующих форматам ERC721 и ERC1155. В отличие от этого, их реализация, например, на Polkadot, обычно строится непосредственно в блокчейн runtime. Их следует считать NFT и сохранять в таком виде.
- Интеграционные возможности. Чтобы обеспечить максимальную ценность для пользователей, решение для индексирования блокчейна может потребовать интеграции своего индекса данных с другими системами, такими как аналитические платформы или API. Это непросто и требует значительных усилий при проектировании архитектуры.
С распространением технологии блокчейн увеличился объем данных, хранящихся в блокчейне. Это связано с тем, что все больше людей используют технологию, и каждая транзакция добавляет новые данные в блокчейн. Кроме того, технология блокчейн эволюционировала от простых приложений для перевода денег, таких как использование биткойна, к более сложным приложениям, включающим реализацию бизнес-логики в смарт-контрактах. Эти смарт-контракты могут генерировать большие объемы данных, способствуя увеличению сложности и размера блокчейна. Со временем это привело к появлению более крупного и сложного блокчейна.
В этой статье мы рассматриваем поэтапное развитие технологической архитектуры Footprint Analytics в качестве примера для изучения того, как технологический стек Iceberg-Trino решает проблемы, связанные с данными в сети.
Footprint Analytics проиндексировала около 22 публичных блокчейн-данных, а также 17 рынков NFT, 1900 проектов GameFi и более 100 000 коллекций NFT в слой данных семантической абстракции. Это самое комплексное решение для хранения данных блокчейна в мире.
Независимо от данных блокчейна, включающих более 20 миллиардов строк записей финансовых транзакций, которые аналитики данных часто запрашивают. это отличается от журналов ввода в традиционных хранилищах данных.
За последние несколько месяцев мы провели 3 крупных обновления, чтобы соответствовать растущим требованиям бизнеса:
2. Архитектура 1.0 Bigquery
В начале работы Footprint Analytics мы использовали Google Bigquery в качестве хранилища и механизма запросов; Bigquery - отличный продукт. Он молниеносно быстр, прост в использовании, предоставляет динамические арифметические возможности и гибкий синтаксис UDF, что помогает нам быстро выполнять работу.
Однако Bigquery также имеет ряд проблем.
- Данные не сжимаются, что приводит к высоким затратам, особенно при хранении необработанных данных более 22 блокчейнов Footprint Analytics.
- Недостаточный параллелизм: Bigquery поддерживает только 100 одновременных запросов, что не подходит для сценариев с высоким уровнем параллелизма для Footprint Analytics при обслуживании большого количества аналитиков и пользователей.
- Блокировка с Google Bigquery, который является продуктом с закрытым исходным кодом。
Поэтому мы решили изучить другие альтернативные архитектуры.
3. Архитектура 2.0 OLAP
Мы были очень заинтересованы в некоторых продуктах OLAP, которые стали очень популярными. Наиболее привлекательным преимуществом OLAP является время ответа на запрос, которое обычно занимает субсекунды для возврата результатов запроса для огромных объемов данных, а также может поддерживать тысячи одновременных запросов.
Мы выбрали одну из лучших OLAP-баз данных, Doris, чтобы попробовать ее. Этот механизм работает хорошо. Однако в какой-то момент мы столкнулись с другими проблемами:
- Такие типы данных, как Array или JSON, пока не поддерживаются (ноябрь, 2022). Массивы - распространенный тип данных в некоторых блокчейнах. Например, поле topic в журналах EVM. Невозможность вычислений на массивах напрямую влияет на нашу способность вычислять многие бизнес-показатели.
- Ограниченная поддержка для DBT, а также для заявлений о слиянии. Это обычные требования инженеров по обработке данных для сценариев ETL/ELT, где нам нужно обновить некоторые новые индексированные данные.
Учитывая это, мы не могли использовать Doris для всего конвейера данных на производстве, поэтому мы попытались использовать Doris в качестве базы данных OLAP для решения части наших проблем в конвейере производства данных, выступая в качестве механизма запросов и обеспечивая быстрые и высококонкурентные возможности запросов.
К сожалению, мы не могли заменить Bigquery на Doris, поэтому нам приходилось периодически синхронизировать данные из Bigquery в Doris, используя его в качестве механизма запросов. Этот процесс синхронизации имел несколько проблем, одна из которых заключалась в том, что записи обновлений быстро накапливались, когда OLAP-движок был занят обслуживанием запросов внешних клиентов. Впоследствии это сказывалось на скорости процесса записи, и синхронизация занимала гораздо больше времени, а иногда даже становилась невозможной.
Мы поняли, что OLAP может решить несколько стоящих перед нами проблем и не может стать готовым решением Footprint Analytics, особенно для конвейера обработки данных. Наша проблема больше и сложнее, и мы можем сказать, что OLAP как механизм запросов сам по себе был для нас недостаточен.
4. Архитектура 3.0 Айсберг + Трино
Добро пожаловать в архитектуру Footprint Analytics 3.0, полностью пересматривающую базовую архитектуру. Мы переработали всю архитектуру с нуля, чтобы разделить хранение, вычисления и запросы данных на три разные части. Мы учли опыт двух предыдущих архитектур Footprint Analytics и опыт других успешных проектов по работе с большими данными, таких как Uber, Netflix и Databricks.
4.1. Внедрение озера данных
Сначала мы обратили внимание на "озеро данных" - новый тип хранилища структурированных и неструктурированных данных. Озеро данных идеально подходит для хранения данных в сети, поскольку форматы данных в сети широко варьируются от неструктурированных сырых данных до структурированных абстрактных данных, которыми славится Footprint Analytics. Мы рассчитывали использовать озеро данных для решения проблемы хранения данных, а в идеале оно также должно поддерживать основные вычислительные механизмы, такие как Spark и Flink, чтобы интеграция с различными типами вычислительных механизмов по мере развития Footprint Analytics не стала проблемой.
Iceberg очень хорошо интегрируется со Spark, Flink, Trino и другими вычислительными движками, и мы можем выбирать наиболее подходящие вычисления для каждой из наших метрик. Например:
- Для тех, кому требуется сложная вычислительная логика, выбор будет сделан в пользу Spark.
- Flink для вычислений в реальном времени.
- Для простых задач ETL, которые можно выполнить с помощью SQL, мы используем Trino.
4.2. Механизм запросов
После того как Iceberg решил проблемы хранения и вычислений, нам пришлось задуматься о выборе механизма запросов. Вариантов оказалось не так много. Мы рассматривали следующие альтернативы
- Трино: SQL Query Engine
- Престо: SQL Query Engine
- Кююби: Бессерверный Spark SQL
Самое главное, что мы учли, прежде чем углубиться в эту тему, - будущий механизм запросов должен быть совместим с нашей текущей архитектурой.
- Для поддержки Bigquery в качестве источника данных
- Для поддержки DBT, на которую мы полагаемся для получения многих показателей
- Для поддержки метабазы BI-инструмента
Исходя из вышесказанного, мы выбрали Trino, который имеет очень хорошую поддержку Iceberg, а команда была настолько отзывчива, что мы обнаружили ошибку, которая была исправлена на следующий день и выпущена в последней версии на следующей неделе. Это был лучший выбор для команды Footprint, которой также требуется высокая скорость реагирования на внедрение.
4.3. Тестирование производительности
Определившись с направлением, мы провели тест производительности комбинации Trino + Iceberg, чтобы проверить, сможет ли она удовлетворить наши потребности, и, к нашему удивлению, запросы оказались невероятно быстрыми.
Зная, что Presto + Hive был худшим компаратором в течение многих лет во всей этой OLAP-шумихе, сочетание Trino + Iceberg полностью взорвало наши умы.
Вот результаты наших тестов.
случай 1: объединение большого набора данных
Таблица1 объемом 800 ГБ присоединяется к другой таблице2 объемом 50 ГБ и выполняет сложные бизнес-вычисления
случай2: использование большой отдельной таблицы для выполнения различительного запроса
Test sql: select distinct(address) from the table group by day

Комбинация Trino+Iceberg примерно в 3 раза быстрее, чем Doris в той же конфигурации.
Кроме того, есть еще один сюрприз, поскольку Iceberg может использовать такие форматы данных, как Parquet, ORC и т.д., которые будут сжимать и хранить данные. Хранилище таблиц Iceberg занимает лишь около 1/5 пространства других хранилищ данных Размер хранения одной и той же таблицы в трех базах данных следующий:
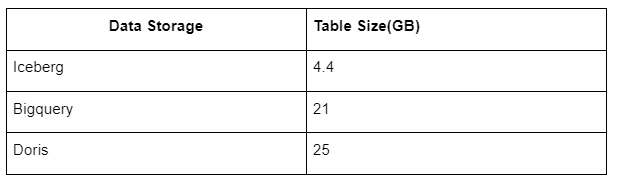
Примечание: Приведенные выше тесты являются примерами, с которыми мы сталкивались в реальном производстве, и приведены только для справки.
4.4. Эффект модернизации
Отчеты о тестировании производительности дали нам достаточную производительность, поэтому нашей команде потребовалось около 2 месяцев, чтобы завершить миграцию, а это диаграмма нашей архитектуры после обновления.
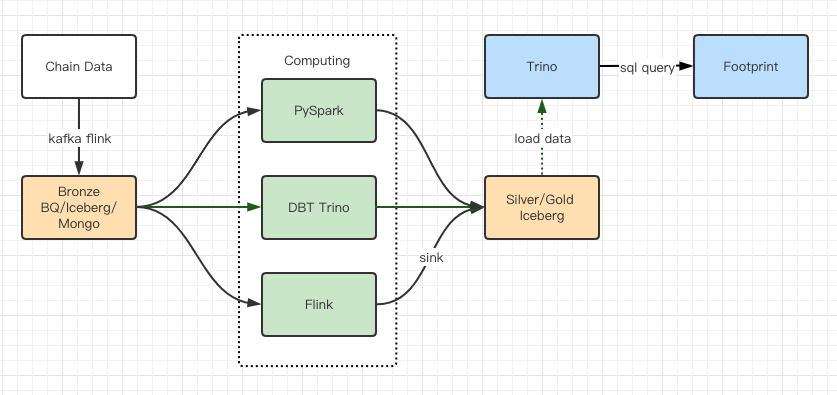
- Несколько компьютерных двигателей соответствуют нашим различным потребностям.
- Trino поддерживает DBT и может напрямую запрашивать Iceberg, поэтому нам больше не нужно заниматься синхронизацией данных.
- Удивительная производительность Trino + Iceberg позволяет нам открыть все данные Bronze (необработанные данные) для наших пользователей.
5. Резюме
С момента своего запуска в августе 2021 года команда Footprint Analytics завершила три модернизации архитектуры менее чем за полтора года, благодаря своему сильному желанию и решимости принести преимущества лучшей технологии баз данных своим пользователям криптовалют и твердому исполнению по внедрению и модернизации базовой инфраструктуры и архитектуры.
Обновление архитектуры Footprint Analytics 3.0 принесло пользователям новый опыт, позволяя пользователям из разных слоев общества получать информацию в более разнообразных сферах использования и применения:
- Footprint, созданный на основе BI-инструмента Metabase, позволяет аналитикам получить доступ к декодированным данным о цепочке, исследовать их с полной свободой выбора инструментов (no-code или hardcord), запрашивать всю историю и перекрестно исследовать наборы данных, чтобы получить глубокие знания в кратчайшие сроки.
- Интеграция данных как в сети, так и вне сети для анализа в web2 + Web3;
- Создавая метрики / запросы поверх бизнес-абстракции Footprint, аналитики или разработчики экономят время на 80% повторяющейся работы по обработке данных и сосредотачиваются на значимых метриках, исследованиях и продуктовых решениях, основанных на их бизнесе.
- Бесшовный опыт от Footprint Web до вызовов REST API, все на основе SQL
- Предупреждения в реальном времени и оперативные уведомления о ключевых сигналах для поддержки инвестиционных решений







