
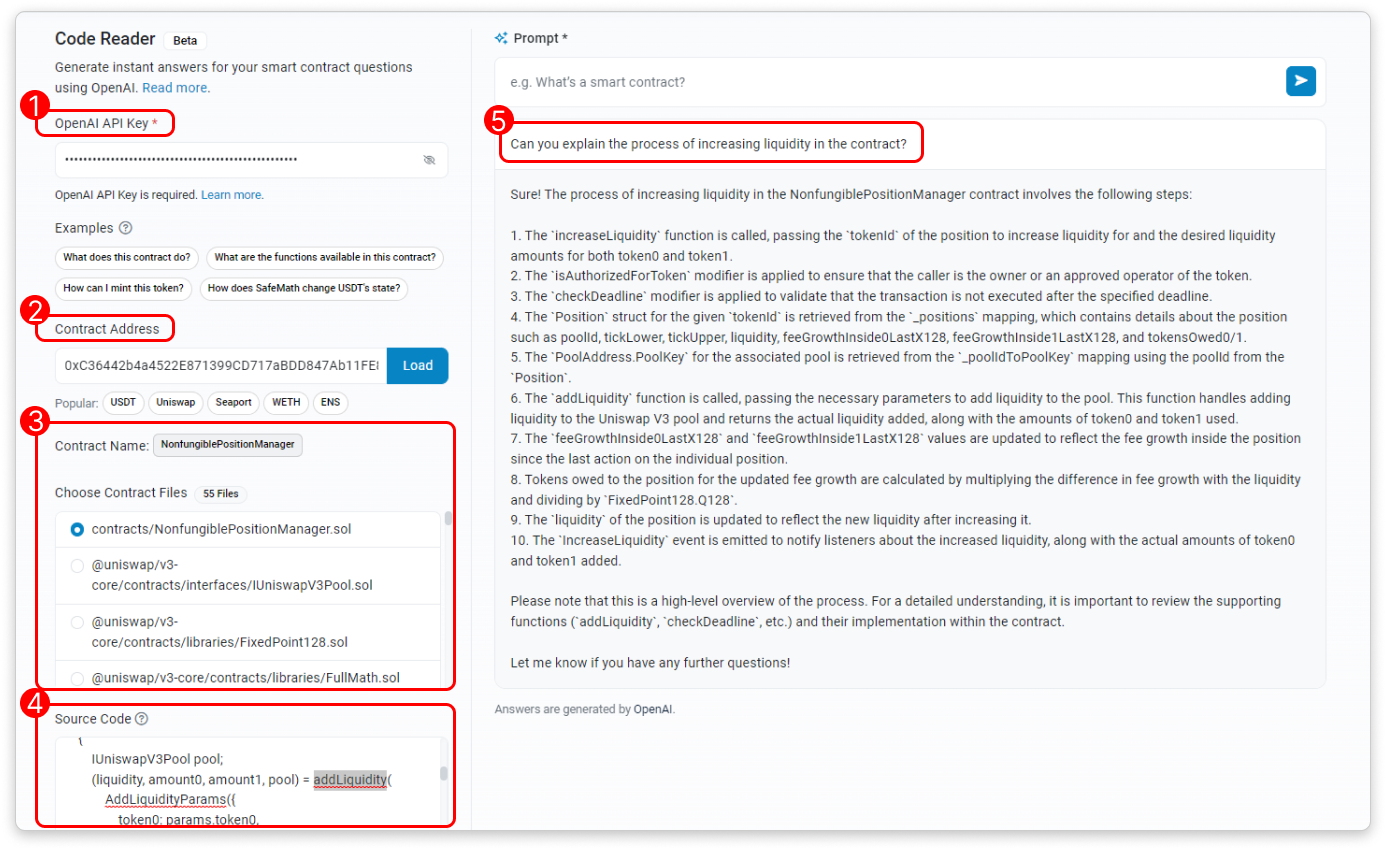
19 июня платформа Etherscan, занимающаяся исследованием и аналитикой блокчейна Ethereum, запустила новый инструмент, получивший название "Code Reader", который использует искусственный интеллект для получения и интерпретации исходного кода определенного адреса контракта. После ввода пользователем запроса, Code Reader генерирует ответ с помощью большой языковой модели OpenAIs (LLM), предоставляя информацию о файлах исходного кода контрактов. Разработчики Etherscan написали:
"Для использования инструмента вам необходим действующий API-ключ OpenAI и достаточный лимит использования OpenAI. Этот инструмент не хранит ваши API-ключи".
Варианты использования Code Reader включают в себя более глубокое понимание кода контрактов с помощью пояснений, генерируемых искусственным интеллектом, получение исчерпывающих списков функций смарт-контрактов, связанных с данными Ethereum, и понимание того, как основной контракт взаимодействует с децентрализованными приложениями (DApps). "После получения файлов контрактов вы можете выбрать конкретный файл исходного кода для чтения. Кроме того, вы можете изменить исходный код непосредственно в пользовательском интерфейсе, прежде чем поделиться им с ИИ", - пишут разработчики.
На фоне бума ИИ некоторые эксперты предупреждают о целесообразности нынешних моделей ИИ. Согласно недавнему отчету, опубликованному сингапурской венчурной компанией Foresight Ventures, "ресурсы вычислительной мощности станут следующим большим полем битвы на ближайшее десятилетие". При этом, несмотря на растущий спрос на обучение больших моделей ИИ в децентрализованных сетях распределенных вычислительных мощностей, исследователи отмечают, что существующие прототипы сталкиваются со значительными ограничениями, такими как сложная синхронизация данных, оптимизация сети, конфиденциальность данных и проблемы безопасности.
В одном из примеров исследователи Foresight отметили, что для обучения большой модели со 175 миллиардами параметров с одинарной точностью представления с плавающей точкой потребуется около 700 гигабайт. Однако распределенное обучение требует, чтобы эти параметры часто передавались и обновлялись между вычислительными узлами. В случае 100 вычислительных узлов, каждый из которых должен обновлять все параметры на каждом шаге, модель потребует передачи 70 терабайт данных в секунду, что значительно превышает возможности большинства сетей. Исследователи подытожили:
"В большинстве сценариев небольшие модели ИИ все еще являются более целесообразным выбором, и их не стоит упускать из виду слишком рано, в прилив FOMO на большие модели".Источник







