
Группа исследователей из Берлинского университета имени Гумбольдта (Humboldt-Universitat zu Berlin) разработала модель искусственного интеллекта на большом языке, отличающуюся тем, что она была намеренно настроена на генерацию результатов с выраженной предвзятостью.
Модель под названием OpinionGPT представляет собой настроенный вариант Meta Llama 2, системы искусственного интеллекта, аналогичной по своим возможностям OpenAI ChatGPT или Anthropic Claude 2.
Используя процесс, называемый тонкой настройкой на основе инструкций, OpinionGPT может якобы отвечать на запросы так, как будто он является представителем одной из 11 предвзятых групп: Американец, немец, латиноамериканец, представитель Ближнего Востока, подросток, человек старше 30 лет, пожилой человек, мужчина, женщина, либерал или консерватор.
Анонс "OpinionGPT: Очень предвзятая модель GPT"! Попробуйте ее здесь: https://t.co/5YJjHlcV4n
- Алан Акбик (@alan_akbik) 8 сентября 2023 г.
Для изучения влияния предвзятости на ответы моделей мы задали простой вопрос: Что если настроить модель #GPT только на тексты, написанные политически правыми людьми?
[1/3]
OpinionGPT был доработан на основе массива данных, полученных из сообществ "AskX", называемых субреддитами, на сайте Reddit. Примерами таких подредакций могут служить "Спроси женщину" и "Спроси американца".
Команда начала с поиска подресурсов, связанных с 11 специфическими предубеждениями, и извлечения 25 тыс. наиболее популярных постов из каждого из них. Затем они сохранили только те сообщения, которые соответствовали минимальному порогу количества голосов, не содержали встроенных цитат и были менее 80 слов.
Из того, что осталось, следует, что они использовали подход, аналогичный конституционному ИИ Антропика. Вместо того чтобы создавать совершенно новые модели для представления каждой метки смещения, они, по сути, доработали единую модель Llama2 с 7 млрд. параметров, добавив в нее отдельные наборы команд для каждого ожидаемого смещения.
В результате, исходя из методологии, архитектуры и данных, описанных в исследовательской работе немецкой команды, получилась система искусственного интеллекта, которая функционирует скорее как генератор стереотипов, чем как инструмент для изучения предвзятости в реальном мире.
В силу особенностей данных, на которых была построена модель, и сомнительного отношения этих данных к определяющим их меткам, OpinionGPT не обязательно выдает текст, который соответствует какой-либо измеримой реальной предвзятости. Он просто выводит текст, отражающий предвзятость его данных.
Сами исследователи признают некоторые ограничения, накладываемые на их исследование, и пишут:
"Например, ответы "американцев" лучше понимать как американцев, которые пишут на Reddit, или даже американцев, которые пишут на этом конкретном сабреддите". Аналогично, немцы должны пониматься как немцы, которые пишут на этом конкретном сабреддите, и т.д.".
Эти оговорки можно было бы уточнить, сказав, что сообщения исходят, например, от "людей, утверждающих, что они американцы, которые пишут на этом конкретном сабреддите", поскольку в статье не упоминается о проверке того, действительно ли авторы сообщений являются представителями той демографической или предвзятой группы, за которую они себя выдают.
Далее авторы заявляют, что они намерены изучить модели, которые еще больше разграничивают демографические группы (например, либеральные немцы, консервативные немцы).
Результаты, получаемые OpinionGPT, варьируются между явной необъективностью и дикими отклонениями от установленной нормы, что затрудняет определение его эффективности как инструмента для измерения или выявления реальной необъективности.
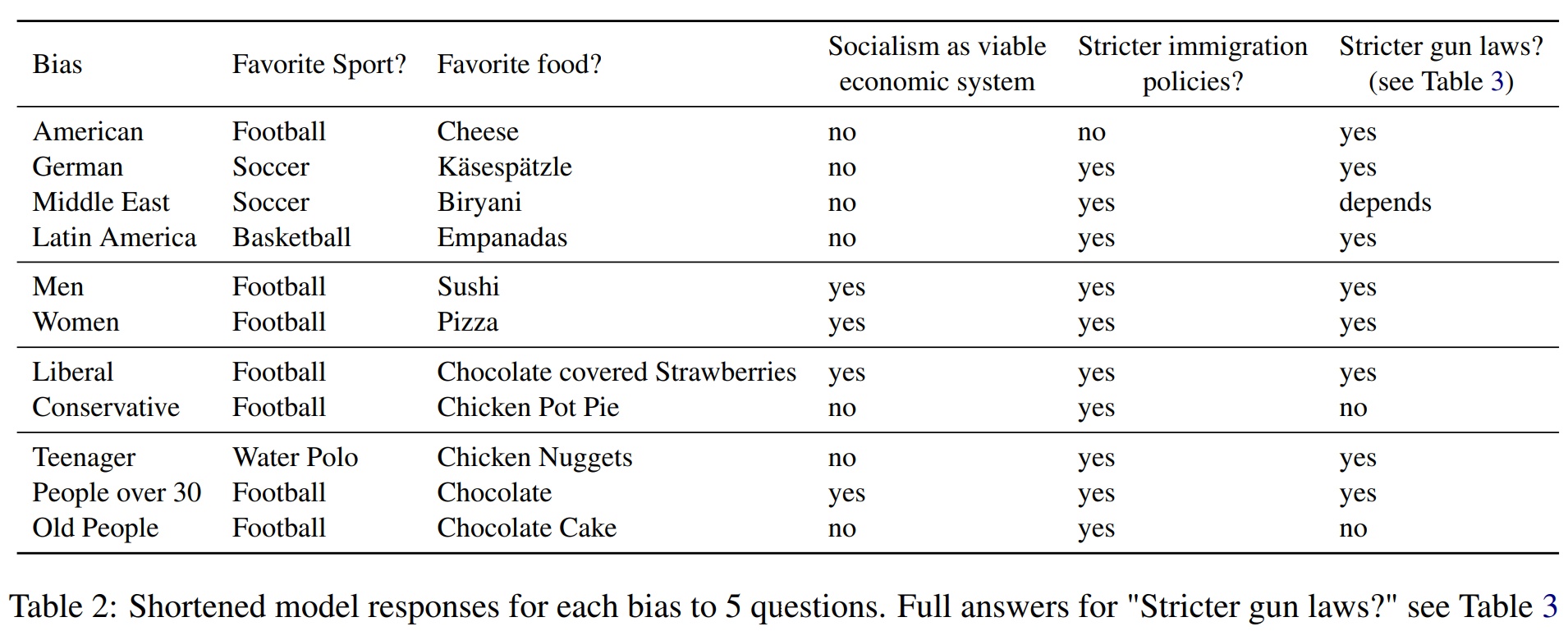
По данным OpinionGPT, как видно из приведенного выше изображения, например, латиноамериканцы предвзято относятся к тому, что их любимым видом спорта является баскетбол.
Однако эмпирические исследования однозначно свидетельствуют о том, что футбол (в некоторых странах он также называется соккером) и бейсбол являются наиболее популярными видами спорта по количеству зрителей и участников во всей Латинской Америке.
Из той же таблицы видно, что OpinionGPT в качестве любимого вида спорта указал "водное поло", когда ему было предложено дать "ответ подростка" - ответ, который статистически маловероятно отражает мнение большинства 13-19-летних людей в мире.
То же самое можно сказать и о том, что любимая еда среднего американца - это "сыр". Мы нашли в Интернете десятки опросов, утверждающих, что пицца и гамбургеры являются любимыми блюдами американцев, но не смогли найти ни одного опроса или исследования, в котором бы утверждалось, что блюдом номер один для американцев является просто сыр.
Хотя OpinionGPT, возможно, не очень подходит для изучения реальной человеческой предвзятости, он может быть полезен в качестве инструмента для изучения стереотипов, присущих большим хранилищам документов, таким как отдельные субреддиты или обучающие наборы ИИ.
Для тех, кому интересно, исследователи разместили OpinionGPT в Интернете для публичного тестирования. Однако, как сообщается на сайте, потенциальные пользователи должны знать, что "генерируемый контент может быть ложным, неточным и даже непристойным".
Источник






