
Около двух десятков исследователей из Университета Цинхуа, Университета штата Огайо и Калифорнийского университета в Беркли совместно создали метод измерения возможностей больших языковых моделей (LLM) в качестве реальных агентов.
Такие LLM, как OpenAI`s ChatGPT и Anthropic`s Claude, за последний год произвели фурор в мире технологий, поскольку передовые "чат-боты" доказали свою полезность в решении различных задач, включая кодирование, торговлю криптовалютой и создание текстов.
Как правило, эти модели оцениваются по их способности выдавать текст, воспринимаемый как человекоподобный, или по их оценкам в тестах, рассчитанных на работу с обычным языком. Для сравнения, по теме LLM-моделей как агентов опубликовано гораздо меньше работ.
Агенты искусственного интеллекта выполняют конкретные задачи, например, следуют набору инструкций в определенной среде. Например, исследователи часто обучают агента искусственного интеллекта ориентироваться в сложной цифровой среде в качестве метода изучения использования машинного обучения для безопасной разработки автономных роботов.
Традиционные агенты машинного обучения, подобные тому, что показан в видеоролике выше, обычно не строятся как LLM из-за непомерно высоких затрат на обучение таких моделей, как ChatGPT и Claude. Тем не менее, самые крупные LLM показали себя в качестве агентов.
Группа специалистов из Цинхуа, штата Огайо и Калифорнийского университета в Беркли разработала инструмент AgentBench для оценки и измерения возможностей LLM-моделей в качестве реальных агентов, что, по их утверждению, является первым в своем роде.
Как говорится в препринте, основной задачей при создании AgentBench было выйти за рамки традиционных сред обучения ИИ - видеоигр и физических симуляторов - и найти способы применения способностей LLM к решению реальных задач, чтобы их можно было эффективно измерить.
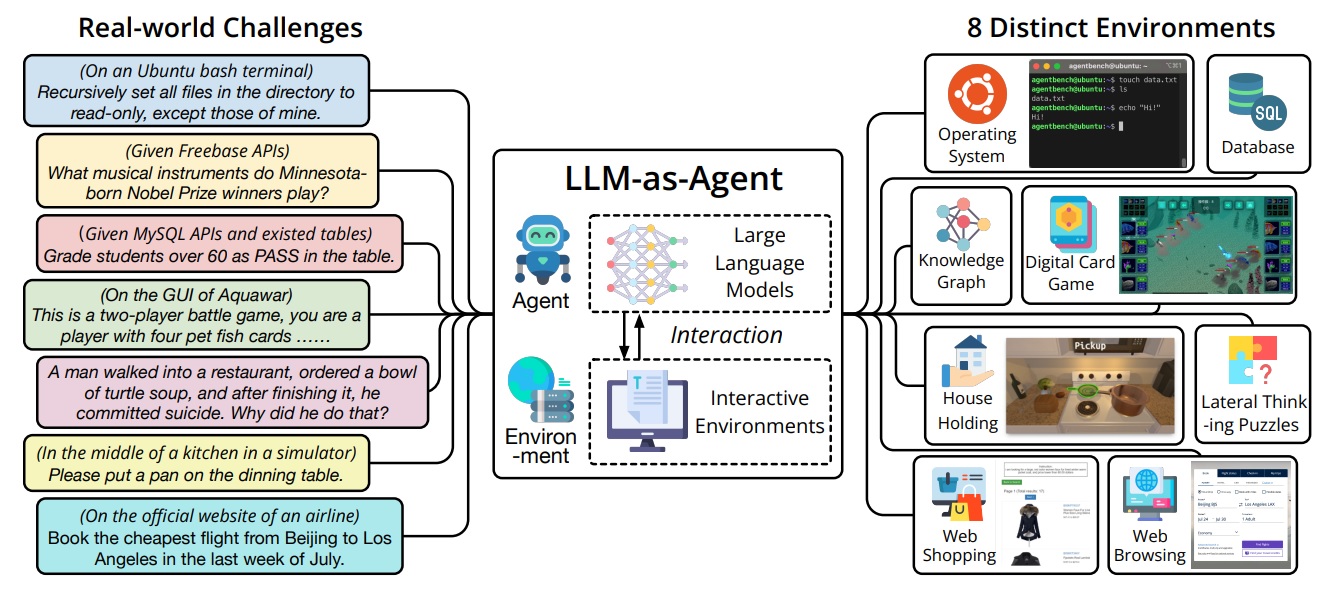
В результате они пришли к многомерному набору тестов, измеряющих способность модели выполнять сложные задачи в различных условиях.
Среди них - выполнение моделей функций в базе данных SQL, работа в операционной системе, планирование и выполнение работ по уборке дома, покупка товаров через Интернет и ряд других задач высокого уровня, требующих пошагового решения проблем.
Согласно статье, самые крупные и дорогие модели значительно превосходят модели с открытым кодом:
"Мы провели комплексную оценку 25 различных LLM с помощью AgentBench, включая как модели на базе API, так и модели с открытым исходным кодом. Наши результаты показывают, что модели высшего уровня, такие как GPT-4, способны решать широкий спектр реальных задач, что указывает на потенциал разработки мощного, постоянно обучающегося агента".
Исследователи заявили, что "лучшие LLM становятся способными решать сложные реальные задачи", но добавили, что конкурентам с открытым исходным кодом еще предстоит пройти "долгий путь".
Источник






