
OpenAI создал новаторскую модель генеративного искусственного интеллекта (ИИ) под названием DALL-E, которая превосходно справляется с созданием отличительных, невероятно детализированных визуальных образов из текстовых описаний. В отличие от обычных моделей создания картинок, DALL-E может создавать оригинальные изображения в ответ на заданные текстовые подсказки, демонстрируя свою способность понимать и преобразовывать вербальные концепции в визуальные представления.
В процессе обучения DALL-E использует обширную коллекцию пар "текст-изображение". Он учится связывать визуальные сигналы с семантическим значением текстовых инструкций. В ответ на текстовую подсказку DALL-E создает изображение из образца изученного вероятностного распределения изображений.
Модель создает визуально последовательное и контекстуально релевантное изображение, соответствующее предоставленной подсказке, объединяя текстовый ввод с представлением латентного пространства. В результате DALL-E способен создавать широкий спектр креативных изображений на основе текстовых описаний, расширяя границы генеративного ИИ в области синтеза изображений.
Как работает DALL-E?
Генеративная модель ИИ DALL-E может создавать невероятно подробные визуальные образы на основе словесных описаний. Чтобы достичь этой способности, она использует идеи из языка и обработки изображений. Вот описание того, как работает DALL-E:
Учебные данные
Для обучения DALL-E используется большой набор данных, состоящий из пар фотографий и связанных с ними текстовых описаний. Связь между визуальной информацией и письменным представлением изучается моделью с помощью этих пар "изображение-текст".
Архитектура автокодировщика
DALL-E построен с использованием архитектуры автокодера, состоящей из двух основных частей: кодера и декодера. Кодер получает изображение и уменьшает его размеры для создания представления, называемого латентным пространством. Затем декодер использует это представление скрытого пространства для создания изображения.
Обусловленность текстовыми подсказками
DALL-E добавляет механизм кондиционирования к обычной архитектуре автоэнкодера. Это означает, что DALL-E подвергает свой декодер текстовым инструкциям или объяснениям во время создания изображений. Текстовые подсказки влияют на внешний вид и содержание создаваемого изображения.
Представление латентного пространства
DALL-E учится отображать визуальные сигналы и письменные подсказки в общем латентном пространстве, используя технику представления латентного пространства. Представление латентного пространства служит связующим звеном между визуальным и вербальным миром. DALL-E может создавать визуальные образы, соответствующие текстовым описаниям, настраивая декодер на определенные текстовые подсказки.
Выборка из латентного пространства
DALL-E выбирает точки из изученного распределения латентного пространства для создания изображений по текстовым подсказкам. Отправной точкой декодера являются эти отобранные точки. DALL-E создает визуальные образы, соответствующие заданным текстовым подсказкам, изменяя отобранные точки и декодируя их.
Обучение и тонкая настройка
DALL-E проходит тщательную процедуру обучения с использованием передовых методов оптимизации. Модель обучают точно воссоздавать оригинальные изображения и выявлять взаимосвязи между визуальными и текстовыми подсказками. Производительность модели улучшается благодаря тонкой настройке, что также позволяет ей создавать различные высококачественные изображения на основе различных текстовых данных.
Примеры использования и применения DALL-E
DALL-E имеет широкий спектр интересных вариантов использования и применения благодаря своей исключительной способности создавать уникальные, тонко детализированные визуальные образы на основе вводимого текста. Некоторые яркие примеры включают:
- Креативный дизайн
- Маркетинг и реклама: DALL-E может быть использован для разработки
- Интерпретируемость и контроль: DALL-E способен создавать визуальные материалы для различных средств массовой информации, включая книги, периодические издания, веб-сайты и социальные сети. Он может преобразовывать текст в сопровождающие его изображения, в результате чего создаются эстетически привлекательные и интересные мультимедийные впечатления.
- Создание прототипа продукта: Создавая визуальные образы на основе словесных описаний, DALL-E может помочь на ранних стадиях проектирования продукта
- Игры и виртуальные миры: навыки производства картин "ДАЛЛ-И" могут помочь в разработке игр
- Наглядные пособия и доступность: DALL-E может помочь в реализации инициатив по обеспечению доступности путем создания визуальных представлений текстового контента, например, визуализации текстовых описаний для людей с нарушениями зрения или разработки альтернативных визуальных презентаций для образовательных ресурсов.
- Ограниченное понимание реальных ограничений: DALL-E может помочь в создании иллюстраций или других визуальных компонентов для повествования. Авторы могут дать текстовое описание объектов или людей, а DALL-E может создать соответствующие изображения, чтобы поддержать повествование и поразить воображение читателя.
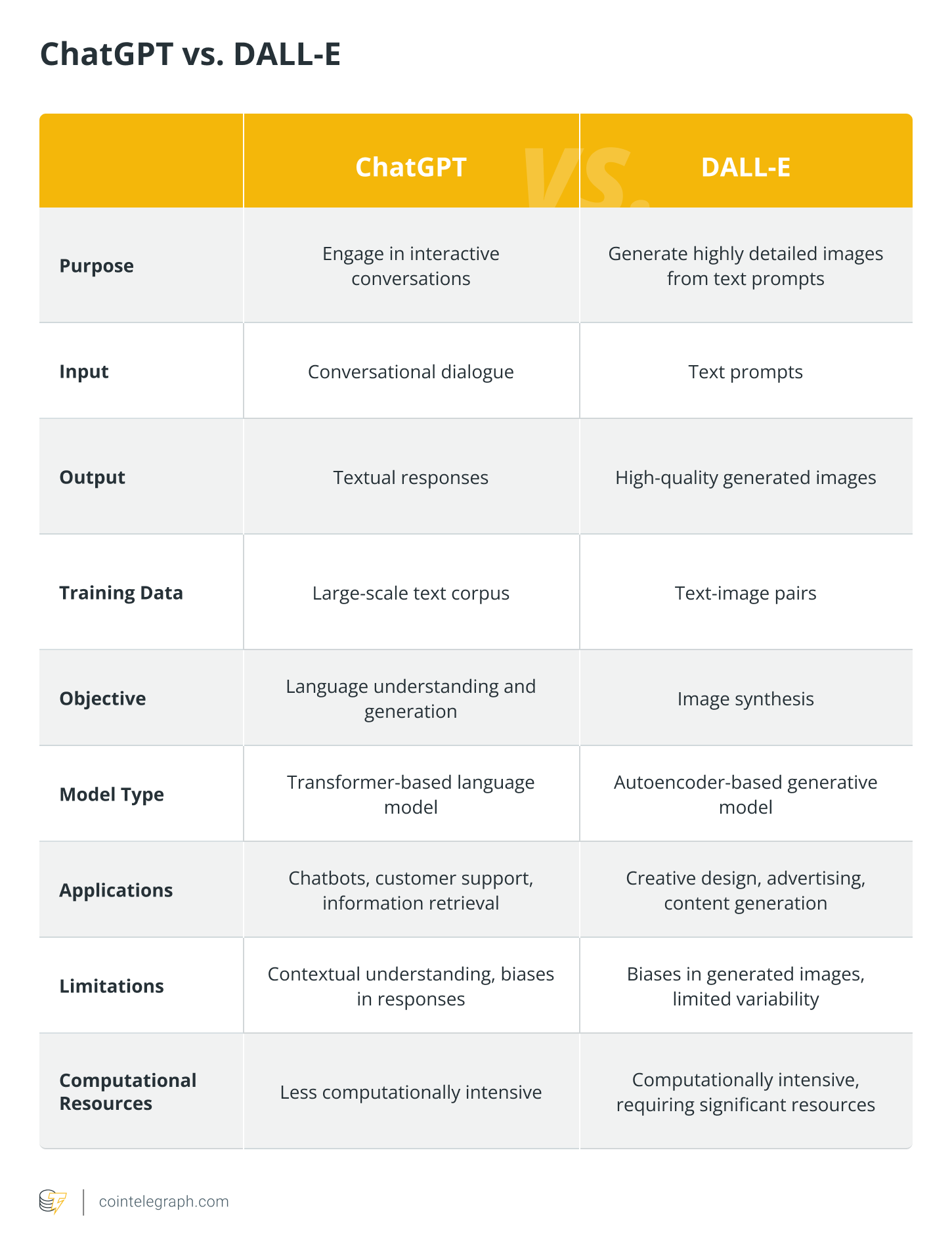
ЧатГПТ против ДАЛЛ-И
ChatGPT - это языковая модель, разработанная
Ограничения DALL-E
У DALL-E есть ограничения, которые необходимо учитывать, несмотря на его возможности по созданию графики из текстовых подсказок. Модель может усилить предрассудки, наблюдаемые в обучающих данных, возможно, увековечивая стереотипы или предубеждения в обществе. За пределами предоставленной подсказки она с трудом справляется с тонкими нюансами и абстрактными объяснениями, поскольку ей не хватает контекстуальной осведомленности.
Сложность модели может затруднить интерпретацию и контроль. DALL-E часто создает очень четкие визуальные образы, но ему может быть трудно придумать другие версии или уловить все возможные варианты. Для создания высококачественных фотографий может потребоваться много усилий и обработки.
Кроме того, модель может давать абсурдные, но визуально привлекательные результаты, которые ig
Источник






