
Компания OpenAI, специализирующаяся на искусственном интеллекте, запустила "GPTBot" - новый инструмент для сбора информации из Интернета, который, по ее словам, может быть использован для улучшения будущих моделей ChatGPT.
"Веб-страницы, просмотренные с помощью пользовательского агента GPTBot, потенциально могут быть использованы для улучшения будущих моделей", - говорится в новом сообщении OpenAI в блоге, добавляя, что это может повысить точность и расширить возможности будущих итераций.
Веб-краулер, иногда называемый веб-пауком, - это тип бота, который индексирует содержимое веб-сайтов в Интернете. Поисковые системы, такие как Google и Bing, используют их для того, чтобы сайты появлялись в результатах поиска.
По словам OpenAI, веб-краулер будет собирать общедоступные данные из всемирной паутины, но при этом отсеивать источники, требующие платного контента, собирающие персональную информацию или содержащие тексты, нарушающие политику компании.
Разбивка
- Shubham Saboo (@Saboo_Shubham_) 7 августа 2023 г.
Компания OpenAI только что запустила GPTBot, веб-краулер, предназначенный для автоматического сбора данных из всего Интернета.
Эти данные будут использованы для обучения будущих моделей искусственного интеллекта, таких как GPT-4 и GPT-5!
GPTBot обеспечивает исключение источников, нарушающих конфиденциальность и находящихся за платными стенами pic.Twitter.com/oR3kY4buaU
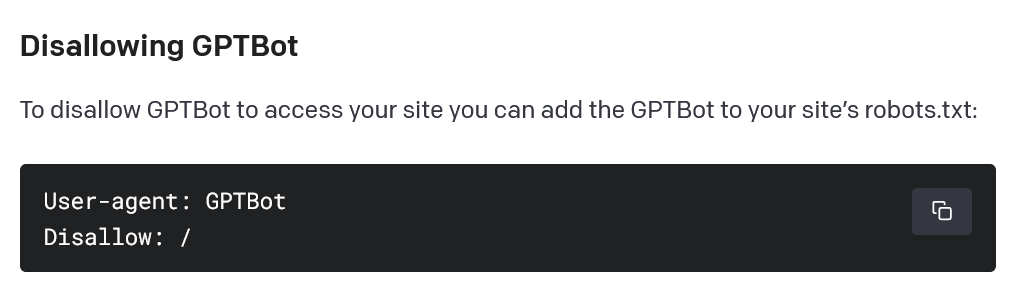
Следует отметить, что владельцы сайтов могут запретить работу веб-краулера, добавив команду "disallow" в стандартный файл на сервере.
Новая гусеничная машина появилась через три недели после того, как фирма подала заявку на товарный знак "GPT-5", ожидаемого преемника нынешней модели GPT-4.
Заявка была подана в Бюро по патентам и товарным знакам США 18 июля и охватывает использование термина "GPT-5", который включает программное обеспечение для человеческой речи и текста на основе ИИ, преобразования аудио в текст, распознавания голоса и речи.
Компания OpenAI подала заявку на регистрацию товарного знака:
- YK aka CS Dojo (@ykdojo) 1 августа 2023 г.
"ГПТ-5"
что включает в себя "программное обеспечение для":
"искусственное воспроизведение человеческой речи и текста"
"преобразование файлов аудиоданных в текст"
"распознавание голоса и речи"
"Обработка языка и речи на основе машинного обучения"
pic.twitter.com/54aJBovDNB
Однако, возможно, наблюдатели пока не хотят задерживать дыхание на следующей итерации ChatGPT. В июне основатель и генеральный директор OpenAI Сэм Альтман заявил, что компания "еще не близка" к началу обучения GPT-5, объяснив это необходимостью проведения нескольких проверок безопасности перед стартом.
Между тем, в последнее время высказываются опасения по поводу тактики сбора данных OpenAI, в частности, по поводу авторских прав и согласия.
В июне японская служба по контролю за соблюдением конфиденциальности выпустила предупреждение для OpenAI по поводу сбора конфиденциальных данных без разрешения, а в апреле Италия временно запретила использование ChatGPT, обвинив его в нарушении различных законов Европейского союза о конфиденциальности.
В конце июня 16 истцов подали коллективный иск против OpenAI, утверждая, что компания, занимающаяся разработкой искусственного интеллекта, получила доступ к частной информации, полученной при взаимодействии с пользователями ChatGPT.
Если эти обвинения подтвердятся, то OpenAI - и компания Microsoft, которая была названа в качестве ответчика, - нарушат Закон о компьютерном мошенничестве и злоупотреблениях (Computer Fraud and Abuse Act), закон, имеющий прецедент для случаев веб-скрейпинга.
Журнал: AI Eye: ИИ-бронирование путешествий - уморительно плохо, 3 странных применения ChatGPT, криптовалютные плагины
Источник






